Introduction
This is a writeup of h1-212; a web-based CTF by HackerOne. You can find the results and other writeups at https://www.hackerone.com/blog/h1-212-ctf-results. The last CTF I completed was for NULLCON way back in 2011 so I’m a tad rusty and this shouldn’t be taken as a how-to. Think of it more as a post-mortem. In order to make the solutions look a bit less like magic, I’ve intentionally included everything I attempted and the underlying thought process, regardless of whether it actually worked. This has predictably resulted in the post being horribly long, so you might want to grab a cup of tea before you begin.
To start, let’s take a look at the CTF introduction:
An engineer of acme.org launched a new server for a new admin panel at http://104.236.20.43/. He is completely confident that the server can’t be hacked. He added a tripwire that notifies him when the flag file is read. He also noticed that the default Apache page is still there, but according to him that’s intentional and doesn’t hurt anyone. Your goal? Read the flag!
As expected, the only visible thing on 104.236.20.43 was a taunting default Apache page, which didn’t even have any notable HTTP headers. A familiar and uninspiring sight for bug bounty hunters, it’s often impossible to know if these hide anything interesting.
Finding an entry point
Faced with a dull and surely well-tested piece of attack surface, I decided to hunt for some more interesting content. I launched a series of bruteforce attacks using Burp Intruder and the RAFT wordlists to enumerate supported file extensions, directories, HTML and PHP files. These found absolutely nothing.
While failing to find web content I also launched a full TCP portscan which revealed that SSH was accessible and had password-based authentication enabled, meaning that either I was expected to bruteforce the password, or the challenge creator simply hadn’t bothered to lock the server down. I correctly guessed that it was the latter and moved on.
By this point it was becoming apparent that bruteforcing was on everyone’s mind and the server started to buckle, causing some seriously extravagant response times. 20,000 requests later the file/folder bruteforce attempts had still found nothing, which only left one plausible explanation; the actual admin panel must be located on a non-default virtual host, meaning it would stay hidden until I supplied the correct Host header. The CTF introduction mentioned that the target company was acme.org, but simply supplying ‘acme.org’ didn’t work, so the virtual host must be a subdomain. I didn’t have a subdomain wordlist handy, so I lazily re-used the RAFT directory one:

This worked perfectly, discovering ‘admin.acme.org’:
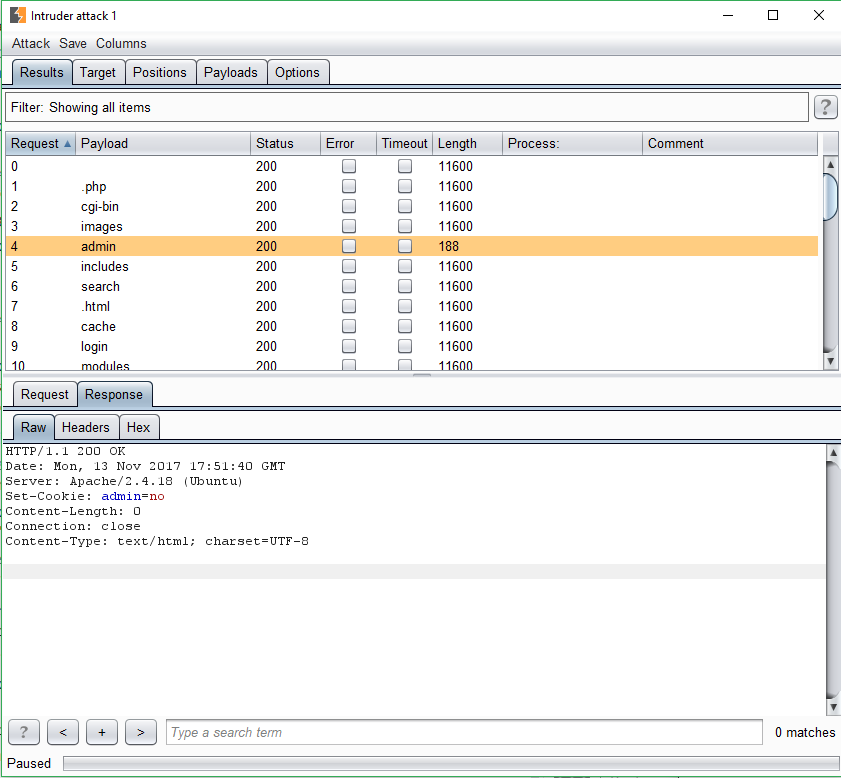
Seeking valid input
The response contained the header ‘Set-Cookie: admin=no’ which is a transparent invitation to send ‘Cookie: admin=yes’. Attempting this resulted in a completely unexpected ‘Method not allowed’ response:

Fortunately, FuzzDB has a wordlist containing every conceivable HTTP method, so I was able to once again brute-force my way towards the flag:
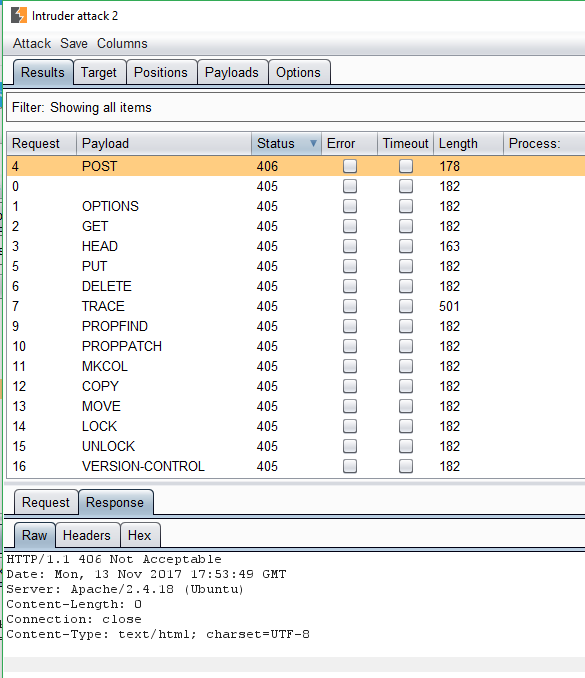
Here we can see that the POST method generates a slightly different response from the others. At this point I got a bit confused and mistakenly decided this must be a server-level error caused by sending a POST request with no body. I tried to resolve this by specifying the Content-Length header without success, then wasted an extremely long five minutes staring at the screen trying to decide what insane custom HTTP header Jobert had thought up.
I then poked the server a bit and made a crucial observation: changing the value of the ‘admin’ cookie resulted in the 406 Not Acceptable response code disappearing:
POST / HTTP/1.1
Host: admin.acme.org
Cookie: admin=yes
Content-Type: application/x-www-form-urlencoded
Content-Length: 9
foo=bar
HTTP/1.1 406 Not Acceptable
Date: Tue, 14 Nov 2017 21:17:20 GMT
Server: Apache/2.4.18 (Ubuntu)
POST / HTTP/1.1
Host: admin.acme.org
Cookie: admin=blah
Content-Type: application/x-www-form-urlencoded
Content-Length: 9
foo=bar
HTTP/1.1 200 OK
Date: Tue, 14 Nov 2017 21:17:45 GMT
Server: Apache/2.4.18 (Ubuntu)
This behaviour indicated that the 406 status code was being generated by custom PHP code rather than Apache itself. This suggested that the application simply didn’t like the Content-Type of my request, and sure enough, changing it to application/json worked:
POST / HTTP/1.1
Host: admin.acme.org
Cookie: admin=yes
Content-Type: application/json
Content-Length: 9
{}
HTTP/1.1 418 I'm a teapot
Server: Apache/2.4.18 (Ubuntu)
Content-Length: 37
Connection: close
Content-Type: application/json
{"error":{"domain":"required"}}
From here, a series of seriously helpful (and sadly realistic) error messages guided me onward:
{"domain":"burpcollaborator.net"}
Response: {"error":{"domain":"incorrect value, .com domain expected"}}
{"domain":"blah.example.com"}
Response: {"error":{"domain":"incorrect value, sub domain should contain 212"}}
Finally, I had a valid input:
{"domain":"212.blah.example.com"}
Response: {"next":"\/read.php?id=1"}
Fetching /read.php?id=1 made the application send a HTTP request to the specified domain, and display the response base64 encoded.
Exploring capabilities
To fingerprint the client, I needed to make it issue a request to a server I could observe. This was problematic as none of burpcollaborator.net, skeletonscribe.net, hackxor.net and uh waf.party end in ‘.com’. Mercifully, it turned out that the application doesn’t validate the domain correctly, so you can fulfil the ‘.com domain’ requirement using the path:
{“domain”:”212.d4ij2t65tt9p9y6yuc.burpcollaborator.net/a.com”}
This resulted in a surprisingly simple request hitting the collaborator:
GET / HTTP/1.0
Host: 212.d4ij2t65tt9p9y6yuc.burpcollaborator.net
The non-standard use of HTTP/1.0 with a Host header and absence of standard HTTP headers like ‘Connection’ imply that this request is being issued by custom code rather than a full-featured HTTP client like curl. This suggests that certain SSRF techniques like abusing redirects probably won’t work. During this process I also noticed that the HTTP request wasn’t sent until I hit the read.php page, which seemed slightly strange, but not particularly useful. This detail turned out to be extremely important later on.
One possibility was that the flag was hidden on the filesystem, and I was expected to find a way to use the SSRF to access local files via the file:/// protocol or perhaps a pseudo-protocol like php://filter. I was able to rule this out by confirming that even the http protocol didn’t work.
Another possibility was that the flag was embedded in the admin panel and only accessible by via the loopback interface. I found I could route requests to loopback using 212.vcap.me/a.com, but this request would be sent with a Host header of ‘212.vcap.me’, meaning that it hit the default virtual host with its beloved default Apache page, rather than the administration panel. I initially attempted to bypass this using 212.foo@admin.acme.org/a.com but the client didn’t support @.
Then I decided that as the HTTP client was so basic, it might be vulnerable to request header injection, letting me inject an extra host header of admin.acme.org. Unfortunately this attack failed too; the application simply failed to return a response when I submitted a new line. When I attempted this attack, I noticed that the corresponding ID number on /read.php incremented by 2 rather than one. This was actually another clue to a critical implementation detail, but at the time I assumed that someone had simply caught up with me in the CTF and disregarded it.
I decided to launch a fresh bruteforce attack, this time on the admin panel, and manually tackled the ‘id’ parameter while that ran. I found that although the input was strictly validated, supplying a high id resulted in a puzzling error: {"error":{"row":"incorrect row"}}
Once again, I disregarded this crucial clue to how the domain-fetch was being implemented, and continued my hunt.
I then checked back on my bruteforce, which had discovered /reset.php, a page that took no arguments and reset the read.php ID counter. Although this page was pretty much useless, its existence implied that the ID might be expected to reach very high numbers - something that would only happen if the SSRF was used in a bruteforce attack.
The obvious target for a bruteforce was localhost; there might be something exploitable bound to loopback like a convenient Redis database. Using the intruder with a list of the most popular 5000 tcp ports borrowed from nmap, I had a discovery on port 1337:
{“domain”:”212.vcap.me:1337/a.com”}
<html>
<head><title>404 Not Found</title></head>
<body bgcolor="white">
<center><h1>404 Not Found</h1></center>
<hr><center>nginx/1.10.3 (Ubuntu)</center>
</body>
</html>
A false solution
Figuring the flag was probably in the web root, I changed the payload to 212.vcap.me:1337/?a.com and received the message “Hmm, where would it be?”
Feeling quite accomplished at getting this far while everyone else was stuck near the start, I made the tactical error of prematurely reporting my progress to Jobert. He quickly grew suspicious of how fast I’d got there, and asked to see the payload I was using:

It turned out that using a ? to hit the root directory and avoid the 404 message was an unintentional bypass and the character was promptly blacklisted, leaving me stuck once again on the 404 page.
Conclusion
I initially tried to work around this by abusing PHP path entities and accessing /index.php/a.com, but the server wasn’t running PHP. I then started to explore why the ID number incremented by two whenever the payload contained \n, and realised that the domains must be inserted into newline-delimited storage. This explained the ‘incorrect row’ error message from earlier. After that, grabbing the flag was simple:
{"domain":"212.vcap.me:1337/z\nvcap.me:1337/flag\nblah.com"}
FLAG:...
In total this challenge took me two and a half hours to complete, and in spite of my many mistakes was still the first person to crack it. Taking part was a great experience, thanks to both the quality of the challenges and the atmosphere and banter supplied in ample by other participants. Thanks to everyone involved!
